本篇文章结合代码来介绍大模型高效微调技术LoRA,并给出简单的代码实现。
什么是LoRA
LoRA是一种高效的参数微调技术,引入可训练的低秩分解矩阵来调整模型参数,来适应特定的任务和领域
为什么需要LoRA
- ft整个大模型训练成本过高
- 大模型中参数量巨大,可能是冗余的,参数有更小的内在维度
LoRA是如何实现的
下面本节将从基本原理与代码实现两个角度介绍LoRA
LoRA的基本原理
在LoRA的实现中,我们引入了两个低秩矩阵A和B。在训练过程中,我们冻结了预训练模型的参数,仅对降维矩阵A和升维矩阵B进行训练。最终的输出可以表示为h = Wx + BAx。
其中,A矩阵通过高斯随机初始化,而B用0初始化,保证了训练初期△W仍然为0,使得模型优化初始点和原始大模型保持一致。
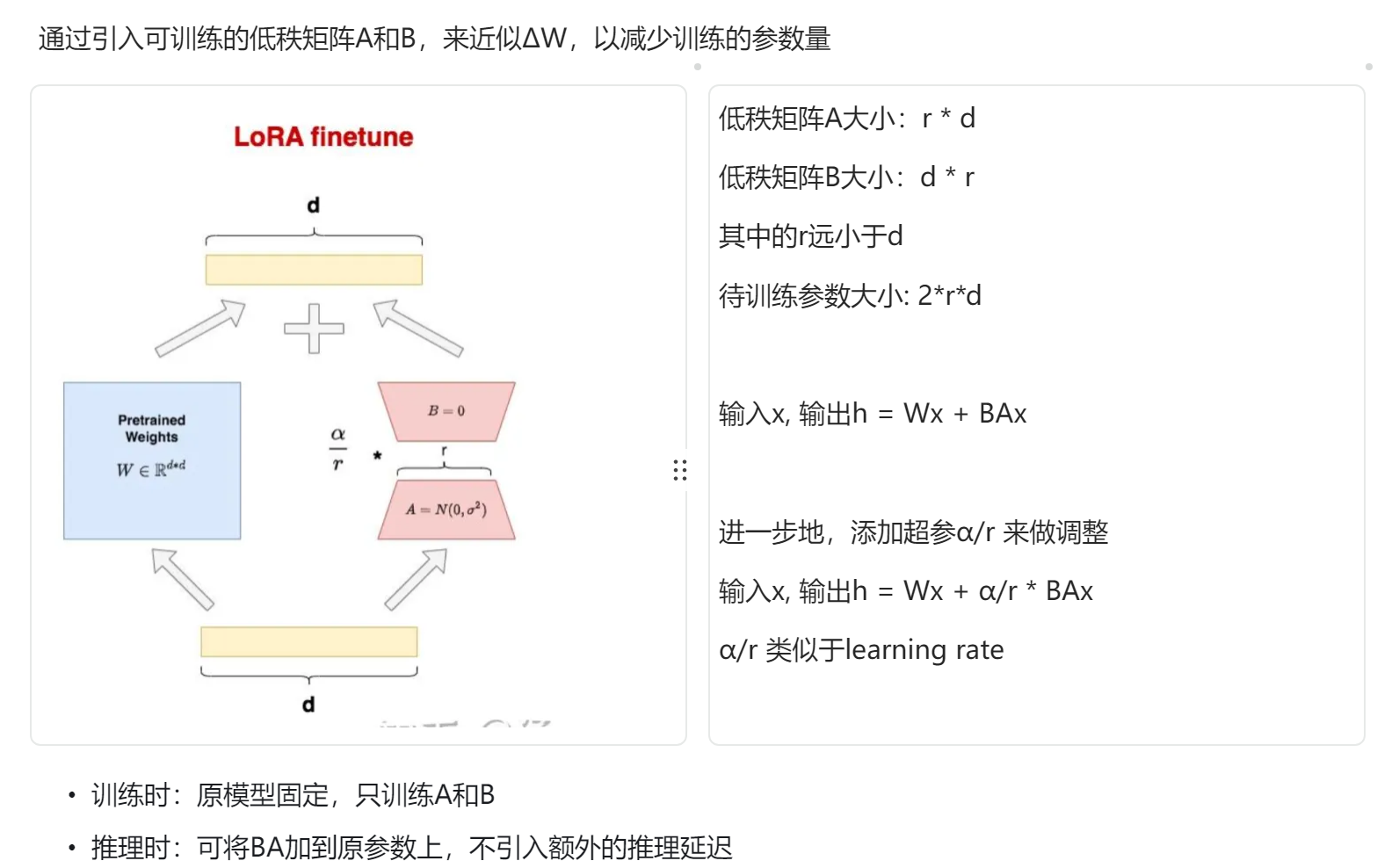
通过这种方式,我们可以显著减少微调所需的参数量。假设原始维度d = 1k,秩为r = 2 , r << d
全参微调: △W = d * d = 100w
lora微调: △W = d * r + r * d = 4K
微调参数量节省了 100w / 4k = 250倍。
在训练完成后,我们可以将A * B^T加到W上,这样在推理时不会引入额外的延迟,从而实现高效的模型推理。
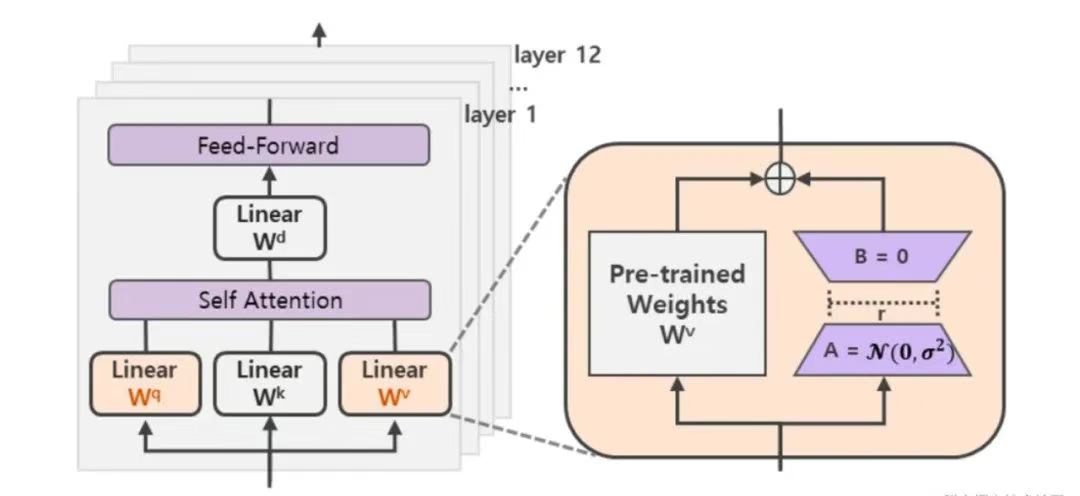
本质上可以将这种方法应用到任何一个参数矩阵中,来减少可训练的参数量。
在Transformer的自注意力模块中,就有权重矩阵Wq, Wk, Wv, Wo,在MLP模块中,就有升维矩阵up_proj和降维矩阵down_proj。
LoRA代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class LinearLoRA(nn.Module):
def __init__(self,
in_features,
out_features,
rank,
alpha):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.rank = rank
self.alpha = alpha
self.pre_trained_weight = nn.Linear(in_features, out_features)
self.pre_trained_weight.weight.requires_grad = False
self.pre_trained_weight.bias.requires_grad = False
self.lora_A = nn.Parameter(torch.zeros(in_features, rank))
nn.init.kaiming_normal_(self.lora_A, a = 0.01)
self.lora_B = nn.Parameter(torch.zeros(rank, out_features))
self.scale = self.alpha / self.rank
def forward(self, X):
part1 = self.pre_trained_weight(X)
part2 = X @ self.lora_A @ self.lora_B
part2 = self.scale * part2
output = part1 + part2
return output
|
运行一下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
in_features = 64
out_features = 64
rank = 4
alpha = 8
batch_size = 2
seq_len = 8
X = torch.randn(batch_size, seq_len, in_features)
lora_layer = LinearLoRA(in_features= in_features, out_features= out_features, rank= rank, alpha= alpha)
output = lora_layer(X)
print(output.shape)
|
LoRA与其他高效微调技术的对比
Adapter
在预训练模型中插入小的可训练的适配器模块(比如两层前馈网络),在训练时原始模型参数冻结,而adapter模块被训练。
缺点:插入了额外模块增加层数,影响推理延迟
Prefix Tuning
在输入前添加一些可训练的“前缀”向量,前缀向量可以看做是特定任务的Prompt,用于引导模型进行输出。
缺点:比较难训练,留给前缀的序列长度挤压了输入的序列长度,效果不如ft
P-tuning
前缀可以是通过神经网络生成的连续提示向量,分布在句子的不同位置。
参考资料
LoRA 原理和 PyTorch 代码实现