模型训练显存优化 - 梯度累积
在深度学习的训练过程中,我们经常会遇到显存限制的问题,尤其是在大规模模型训练时,直接使用大批次(Large Batch)进行梯度计算往往会导致显存溢出(Out of Memory, OOM)。为了解决这个问题,梯度累积(Gradient Accumulation) 技术应运而生,它允许在 小批次(Micro-Batch) 的基础上 逐步累积梯度,最后模拟出 等效的大批次(Large Batch),从而提高训练的稳定性,同时避免显存不足的情况。
什么是梯度累积?
通常在训练中,每个 batch 会经过前向传播(Forward Pass)、反向传播(Backward Pass),并立即更新参数(Optimizer Step)。模型训练过程可以看之前的这篇博客:torch代码演示模型训练流程中的梯度变化
前向传播: 得到中间激活值和计算图 -> 计算loss
反向传播: 根据loss和计算图来计算每个参数对应的梯度
参数更新: 利用梯度来更新参数值
但我们不会每次会同时计算多个样本,提高训练速度。但是同时使用多个样本,会造成显存不足的情况。
梯度累积优化显存的方式:
在深度学习训练过程中,显存主要被三类数据占用:
显存占用部分
模型参数(Model Parameters)
梯度(Gradients)
激活值(Activations)
优化器状态(Optimizer States):如动量、二阶矩 (Adam)
存在问题:
当批次比较大时(单步前向传播同时处理的样本较大),这时,每个样本的前向传播中间值都会被存储,以用于后续的梯度计算。而梯度累积就是用于优化这部分显存占用
示例
假设我们原本希望使用 batch_size = 128 进行训练,但由于 GPU 显存不足,我们只能支持 micro_batch_size = 16,此时我们可以:
运行 8 次小批次训练(每次 micro_batch_size=16)。
在每次训练后计算梯度并累积到 param.grad 中,(也就是进行梯度的累加)梯度完成计算后,计算图和激活值就会释放,但不更新参数。
第 8 次训练完成后,执行 optimizer.step() 一次性更新参数,然后 optimizer.zero_grad() 清空梯度。
这样显存占用就会大大减小啦!
小batch size的梯度累积和大batch size的数学等价性
你可能会奇怪,在多次小bs训练时,把梯度进行简单的相加再进行更新,和单次大bs得到的效果会一致吗?
梯度下降的本质是对损失函数 $L$ 求参数 $W$ 的梯度: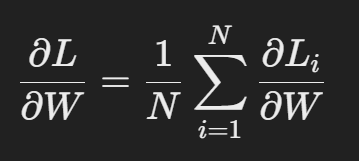
其中:$N$ 是 batch size, $L_i$ 是单个样本的 loss
由于梯度是线性可加的,所以无论是:
一次计算 batch_size=128 的梯度
还是累积 batch_size=16 的梯度 8 次
最终得到的梯度 是完全相同的,只要 optimizer.step() 之前模型参数不变。