DPO算法
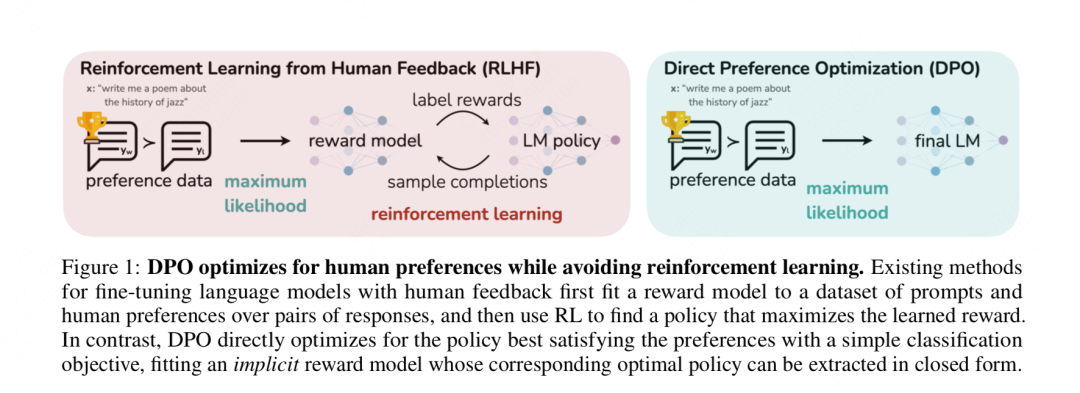
** 一步到位训练对齐模型! **
关键在于,把训练奖励模型的目标函数转换成只和对齐模型相关,这样我们就可以直接训练对齐模型了
- 不依赖于其中的奖励模型rθ,⽽是直接利⽤偏好数据来优化原来的语⾔模型。偏好排序数据有2种情况:
- 2个回答: <prompt_x, chosen_y1, rejected_y2>
- K(K>2)个回答 (可以拆分成两两pair对)
- 不再使用强化学习的方法,通过数学推理,将原始的对齐目标进行简化,通过类似sft的方式,用更简单的步骤训练出对齐模型
开始循序渐进解释dpo loss函数是如何从这个总体优化目标中推导而出的,大家在这个过程中依然牢记两件事:绕过奖励模型最大可能简化优化目标。
第一步:有一个总的对齐人类偏好阶段的优化目标函数,它是在外假设我们已经有了一个奖励模型(函数)r的基础上设计的,我们的目标是找到能使这个优化目标最大化的对齐模型π。而这个优化目标依旧是最大化奖励分数,不要偏离sft模型太远
第二步:我们从这个优化目标出发,找到对齐模型π的显示解(也就是在任意固定的奖励函数r的基础上的π)。也可以反解过来,将最优的奖励模型用最优的对齐模型来表示。

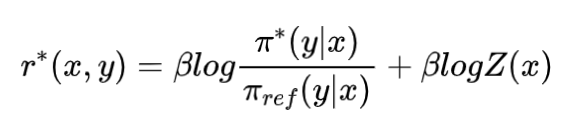
第三步:在实际训练中,我们肯定是在最优的奖励函数上去训练最优的对齐模型π,所以最优奖励模型 -> 最优对齐模型。
第四步:可是我们没有最优奖励模型,我们只有偏好数据,我们尽可能地绕过奖励模型的训练。我们先关注奖励模型的训练目标,然后把第二步得到的用对齐模型表示的奖励模型的解代入到奖励模型的训练目标中,然后我们就能在训练的时候一步到位训练对齐模型。
- 奖励模型的训loss为:
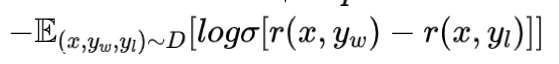
- 奖励模型用对齐模型表示为:
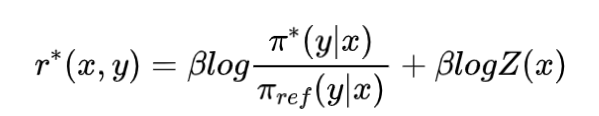
- 带入到这个优化目标中,有:
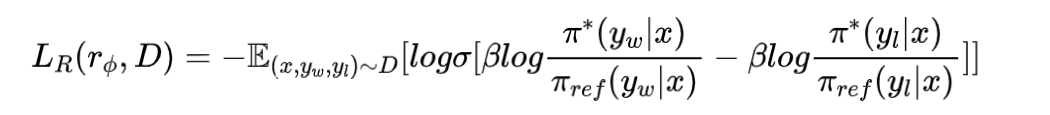
进行一些式子上的改动,把π*标注为πθ,表示是代训练的对齐模型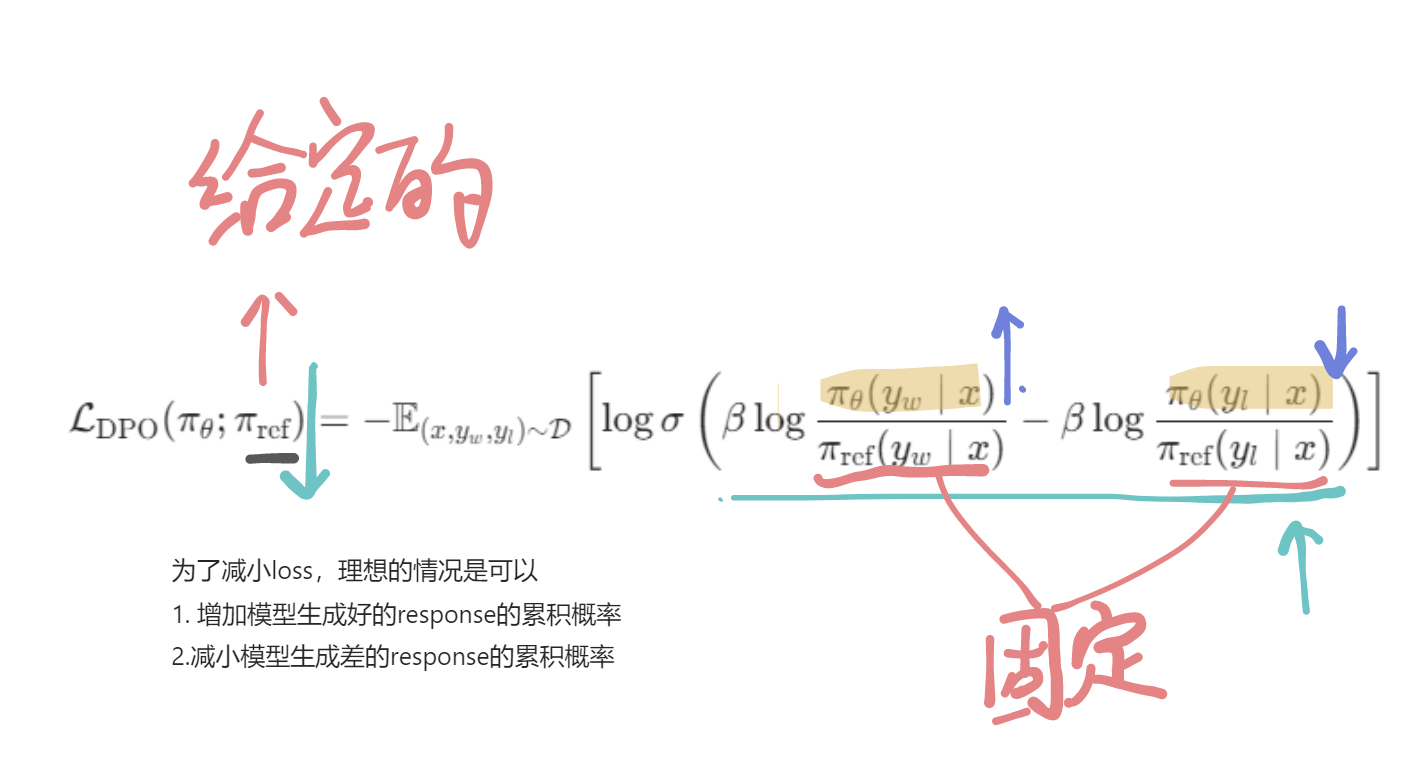
β控制的是对齐模型和sft模型的距离考虑的权重,β越大,对齐模型和sft模型越接近。
扩展: step-KTO,利用了COT的思维链步骤
https://abigail61.github.io/2025/03/04/draft/DPO原理/