结合代码理解各种注意力机制(二):多头注意力机制
前言
这是注意力机制系列的第二篇,在上一篇文章
结合代码理解各种注意力机制(一):自注意力机制中,我们介绍了自注意力机制。此篇文章我们将在自注意力机制的基础上介绍多头注意力机制。
多头注意力机制
概念
多头注意力机制(Multi-Head Attention)是自注意力机制的扩展,它可以通过不同的子空间,来捕捉更多的信息。
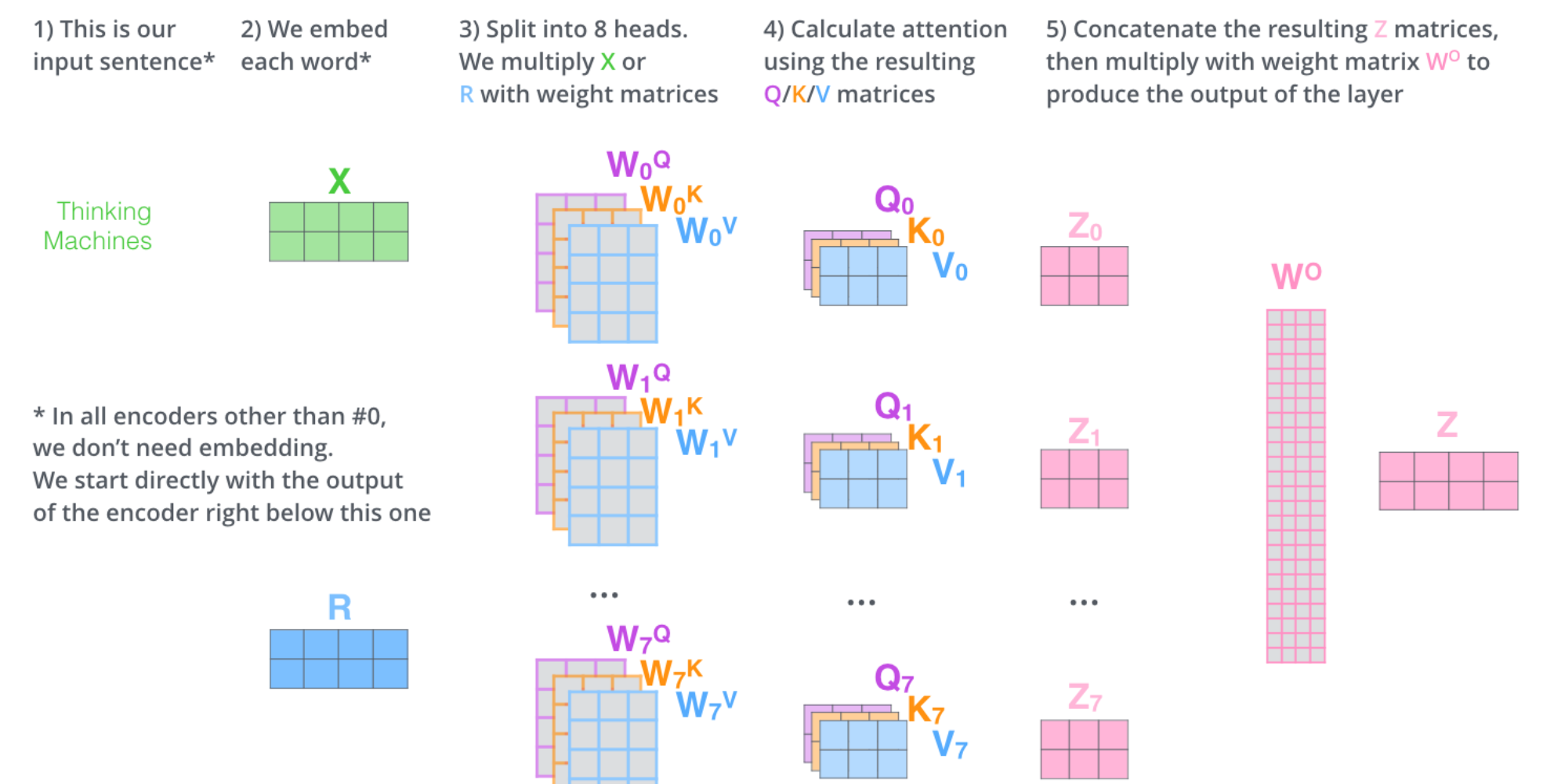
其实,也就是我们可以拥有多组Wq,Wk,Wv,获得多种不同视角的注意力分数,然后将其进行拼接并进行线性变换。
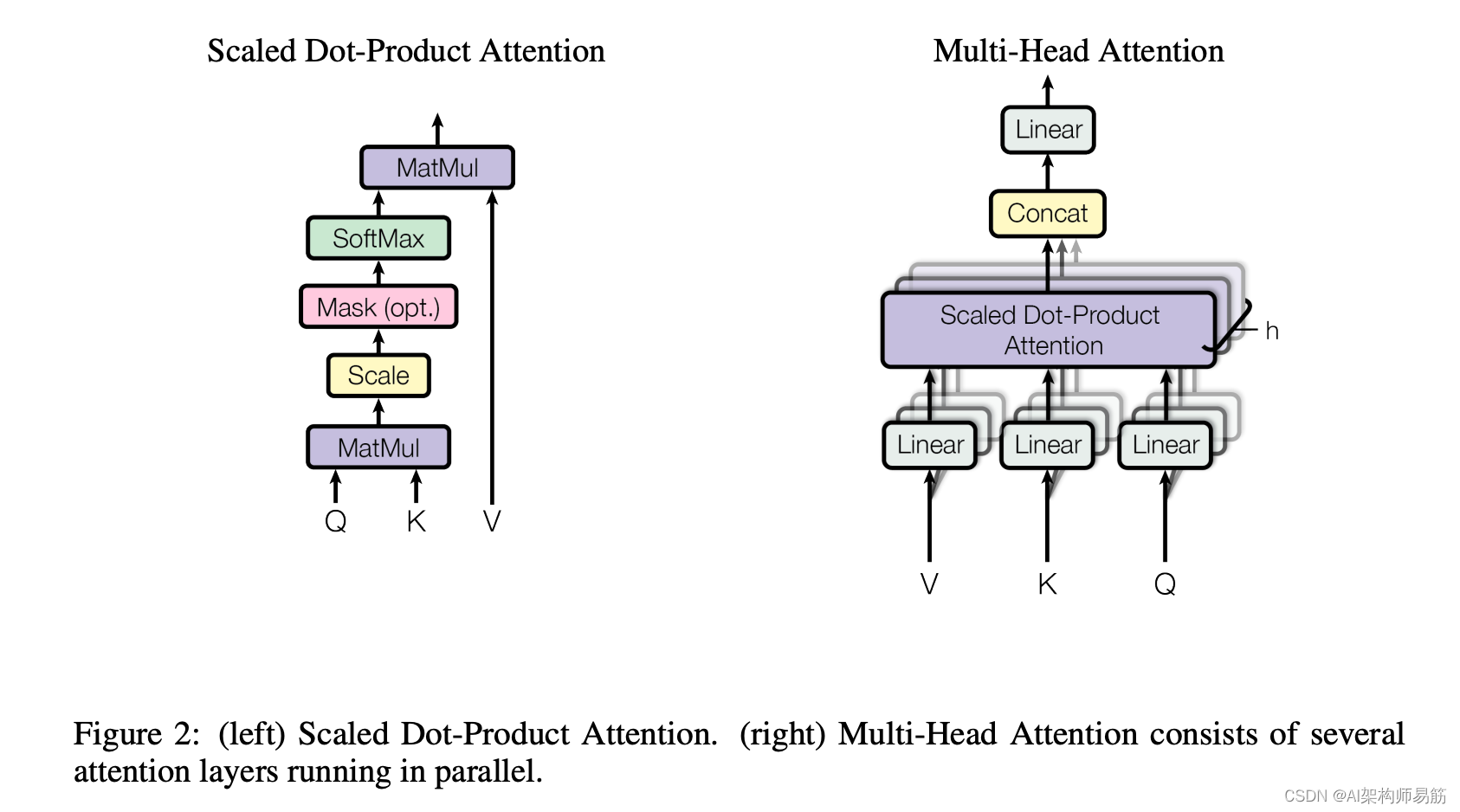
通过多组QKV得到多个注意力分数,然后进行concat拼接,再进行线性变换。

代码实现
在代码实现上,我们可以通过封装上一篇中实现的SelfAttention类,来实现多头注意力机制。
通过使用nn.ModuleList,我们可以将多个自注意力机制的实例封装在一起,然后通过torch.cat进行拼接。拼接完成后,再通过一个nn.Linear建立全连接层进行线性变换,维度为num_heads * d_v, d_v。
MHA类封装:
1 | |
MHA类使用:
1 | |
结果如下:
1 | |
结合代码理解各种注意力机制(二):多头注意力机制
https://abigail61.github.io/2025/01/26/结合代码理解各种注意力机制(二):多头注意力机制/